So etwas, sollte man vermeiden: Mehrfaches laden von Datensätzen in einem Kontext
Das mag im Schulungsumfeld „OK“ sein – Produktiv bedeutet das aber Umstand, Unübersichtlichkeit und Zeit. Schöner ist das bilden eines JSON Datensatzes. Das geht ganz einfach:
Array aus mehreren ArraysJSON Datensatz
Einen Satz laden und durch den JSON Tree selektieren.
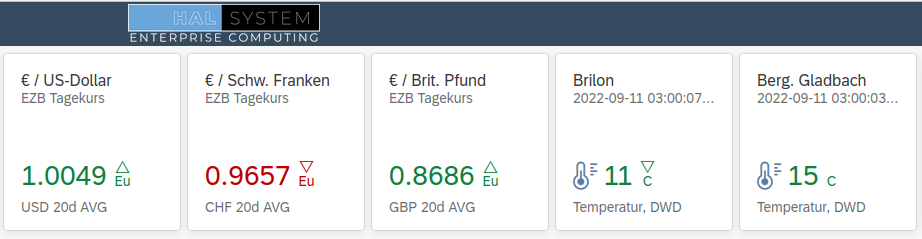
Da scheiden sich die Geister: Datenaggregation und das setzen der Properties eines UI5 Elements nach oder mit der SQL Abfrage? Eine Frage der Sicherheit und des Komforts. Beispiel unsere KPI Seite https://halsec.de
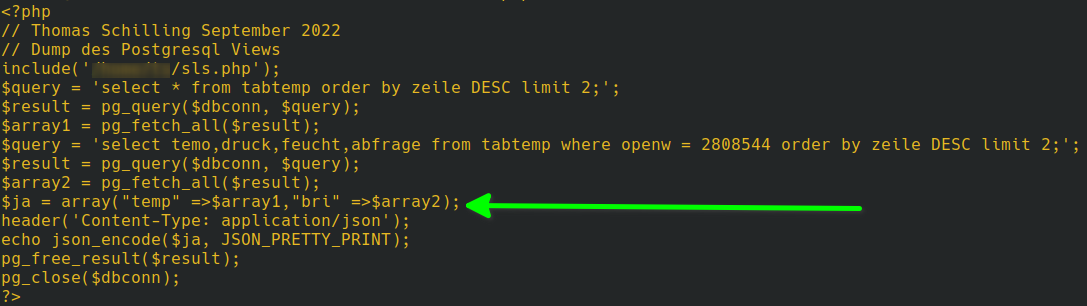
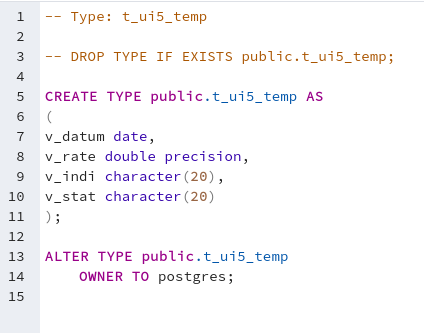
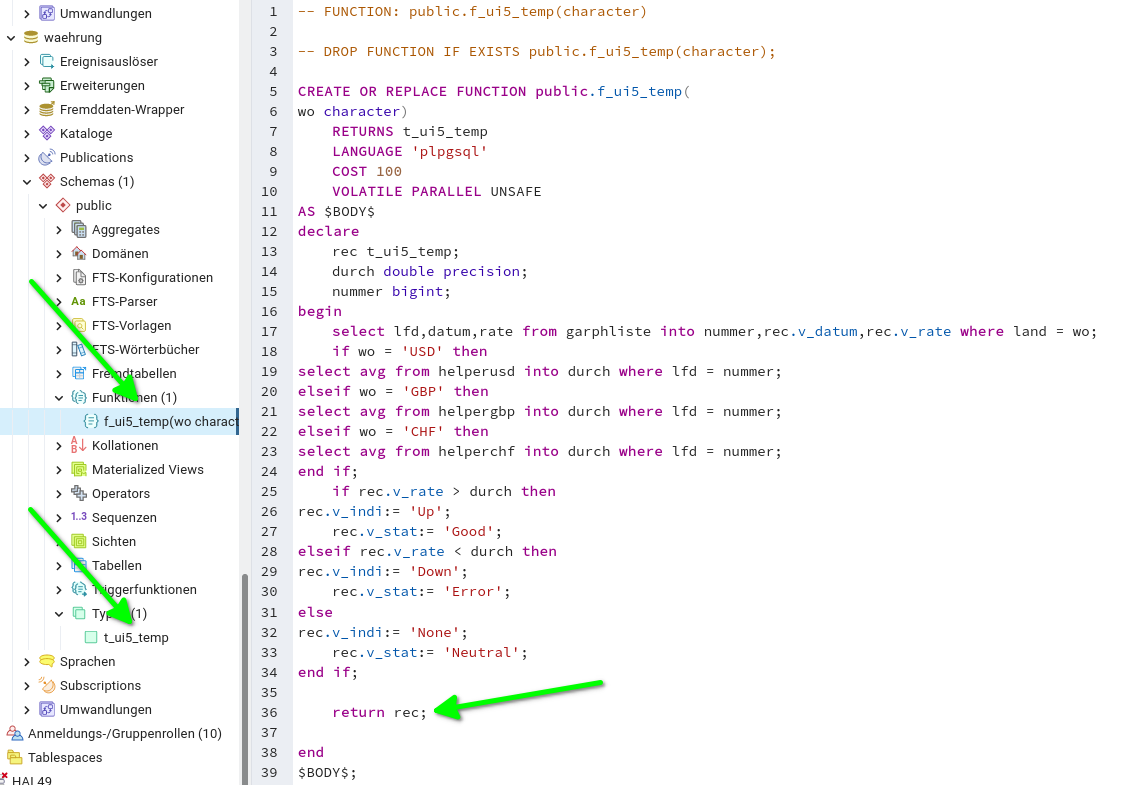
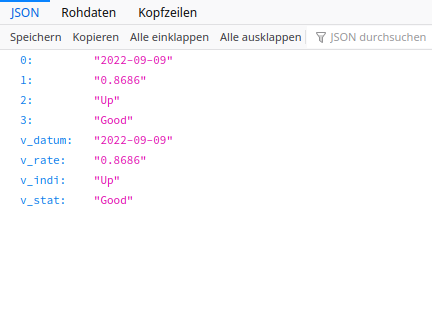
Die Daten für die Kurs Kacheln habe ich aus Basis von PL/pgSQL als Funktion realisiert. Postgresql übernimmt die Selektion der Daten und die Findung der Properties.
Definition des Daten TypsSelektion und Definition des RückgabewertesErgebnis Abfrage der Funktion
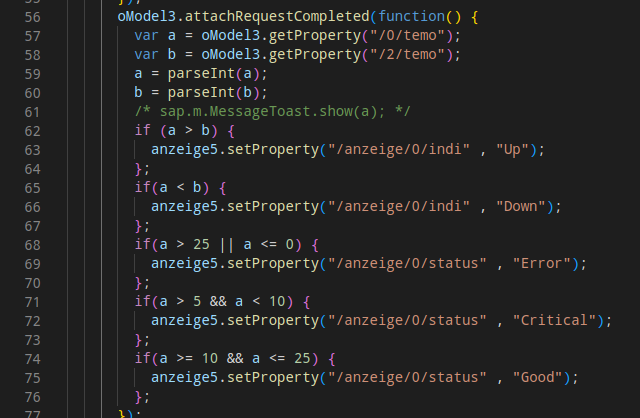
Der JSON Datensatz beinhaltet so alle nötigen Daten zur Darstellung der Kurs Kachel im UI5. So gestaltet sich das JavaScript im UI5 sehr einfach:
(Controller) var anzeige1 = new sap.ui.model.json.JSONModel(); anzeige1.loadData(„https://halsec.de/fetch/ui5_eins.php?wo=USD“); this.byId(„gt2“).setModel(anzeige1, „rates„);
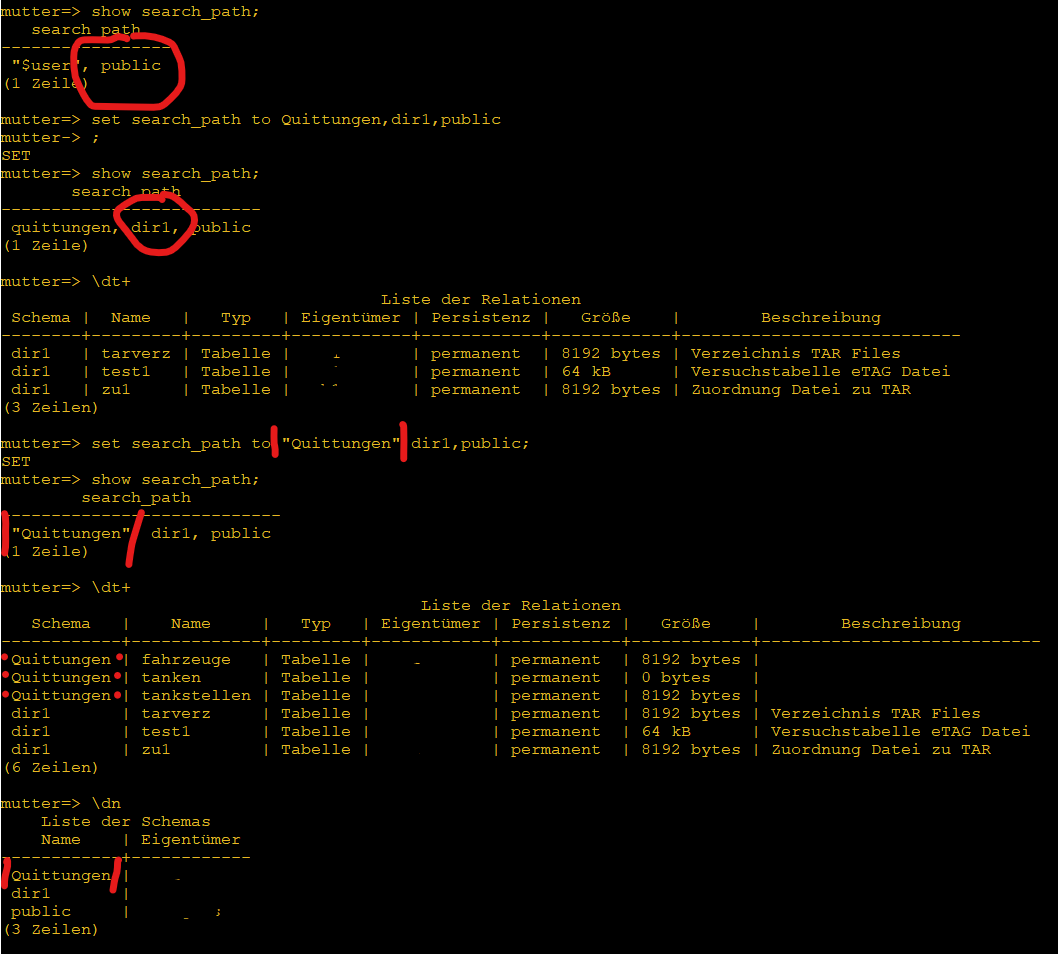
Zur Zeit arbeiten wir im Team an der Programmierung mit zwei unterschiedlichen Datenbank Backend’s: mySQL und Postgres. „Mal eben“ die Struktur einer Tabelle aufrufen, läuft über die Bash CLI unterschiedlich.
[table id=7 /]
Obacht mit Großschreibung im Schema! Ein Schema mit Großschreibung im Suchpfad, wird in Kleinbuchstaben gespeichert. Das Schema ist als String zu maskieren!
Vor geraumer Zeit war das auch Thema im CCGL (Link) – wie nutze ich TAR um Archive verschlüsselt auf einem öffentlichen Laufwerk zu sichern.
Zahlreiche Varianten neben TAR/aespipe/split nutze ich. Eine weitere und sicherere Art ist es, TAR in Kombination mit OpenSSL zu nutzen. Zunächst aber das Handling.
Im CCGL haben wir TAR als Stream durch „split“ in kleinere Pakete zerteilt. Das kann TAR auch alleine:
Wir sehen, analog zum Beispiel im Link, ein Multi-Volume (M), begrenzt auf eine Bandlänge (L) von 1.9GB. Ohne das Script (F) würde der Befehl zum Wechseln des Mediums auffordern, wenn eine Menge von 1.9GB geschrieben wurde. Die Datei, die wir anstatt Band mit (f) konfiguriert haben, wird zur Laufzeit im Parameter TAR_FD (File Descriptor) gehalten und mit dem Script bei jedem „Bandwechsel“ neu gesetzt. Coole Sache! Aus test.tar wird nach den ersten 1.9GB dann 2-test.tar. Mit „V“ setzte ich gerne Label – vergleichbar mit dem Aufkleber den wir früher auf die Band Rollen oder Disketten geklebt haben.
Versuchen wir den Inhalt darzustellen, ohne zu Wissen das es sich um ein Multi Volume Archiv handelt:
Man erkennt die Problematik? Sicherlich wenn man das ganze mit dem Multi Volume Script sieht:
Das Archiv wird nahtlos und vollständig aufgelistet. Es wird nur das Label des ersten Archivs aufgeführt.
Wenn ich Zeit finde, zeige ich wie ich das in meinem jetzigen Projekt gelöst habe und wie man das Archiv verschlüßelt ablegt.
Im CCGL halten wir unsere Raspberry Pi’s mit Ansible synchron. Je nach Aufgabe werden Softwarestände und Code gleich gehalten.
Bestimmte Task sollten aber nicht mit dem allgemeinen Playbook ablaufen: Löschen von Verzeichnissen, unbeabsichtigte Installationen und kein ausserplanmäßiges Update.
Dazu habe ich die kritischen Task’s mit dem Tag „never“ versehen. Das Tag „never“ sorgt dafür, dass dieser Tag „never“ abläuft. Es sei denn, wir geben ihn expliziet an.
Beim Aufruf also, auf den „-t“ Tag und eine eventuelle Beschränkung mit „-l“ auf die im Inventory konfigurierten Maschinen achten!
Ich habe des Öfteren das Problem, das SSH Verbindungen über WLAN sporadisch abbrechen. Bei Backup’s ärgerlich – ich habe hier einen Tipp geschrieben – aber auch das verlieren von getunnelten RDP Verbindungen nervt. In Microsoft Windows Systemen nutze ich PuTTY für SSH Tunnel – mit Hilfe eines kleinen Batchfiles und dem Programm Plink aus dem PuTTY-Paket lässt sich das Problem elegant beheben.
Die Verbindungsparameter vereinbaren wir bequem im UI des Programms PuTTY und merken uns den Namen des gespeicherten Profils. Jetzt erzeugen wir ein Batchfile (Dateiendung .bat)
@echo off
:while
date /T
time /T
C:\Users\irgendwo\plink.exe -batch -N -load profil
if %errorlevel% neq 0 ( goto :while )
Die Argumente für Plink sind analog zu PuTTY. Wenn im Profil Username, Zertifikat, Tunnel hinterlegt ist, kann man mit -batch -N die Shell und jede Nachfrage unterdrücken. Das Batchfile zeigt lediglich Datum und Zeit des Connects sowie Reconnect an.
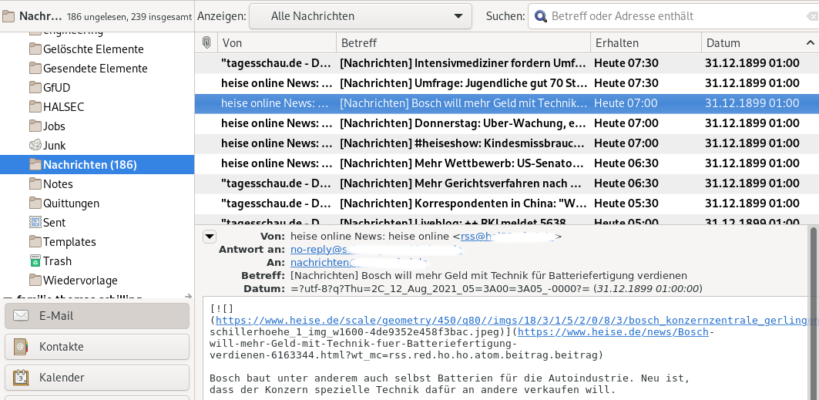
Nicht nur praktisch um allgemein auf dem Laufenden zu bleiben, es kann auch als Firmen internes Mitteilungsorgan genutzt werden. Eine Nachricht an die konfigurierte Mail Adresse wird sicher verteilt und archiviert.
auto. Ordner Nachrichten auf PC, Laptop oder Smartphone
Mailman Archiv
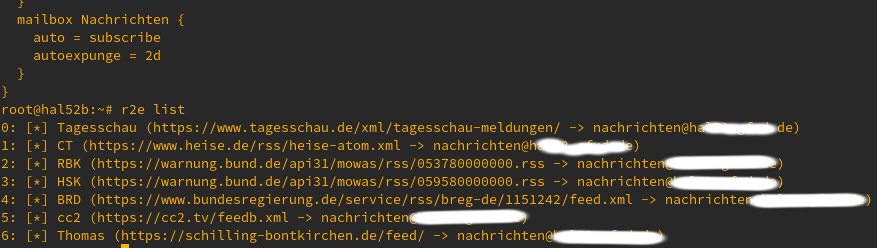
Konfiguration IMAP Ordner 48h Zeit der Vorhaltung. Liste der Feeds.
r2e holt also den RSS Feed ab und sendet ihn als gewöhnliche EMail. Im IMAP Server (hier Dovecot) ist die Lebenszeit der Nachrichten auf 48h konfiguriert. Wichtig, damit die Übersicht erhalten bleibt und der Nutzer nicht selbst löschen muss. Das EMail Postfach gehört Mailman und verteilt die Nachrichten in die Postfächer der entsprechenden Abbonenten und hält ein Archiv vor.
Das nur als Alternative zum ECM System. Welche Lösungen habt Ihr im Betrieb?
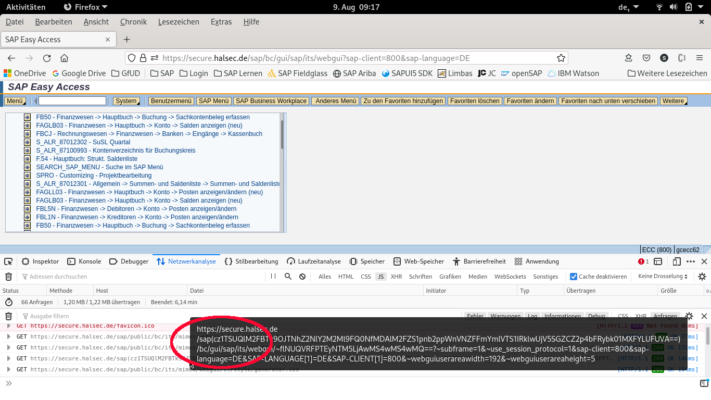
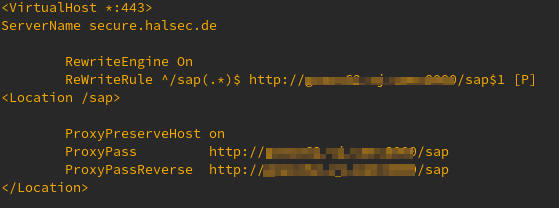
Das Apache2 Modul mod_proxy zur Anbindung des SAP ITS an die Aussenwelt funktioniert recht problemlos wenn es um WebDynpro’s geht.
Will man darüber hinaus auch die WebGUI Online nutzen, gibt es einen Stolperstein. Im Verbindungsaufbau zum WebGUI wird die Session ID (SSO) als POST in der URL ausgetauscht. Das sprengt die Direktive im Filter „/sap“ des Apache welcher dann das „/sap(“ nicht erkennt. Der Prozess bleibt für den User scheinbar stehen.
URL Rewrite im Anmeldeprozess
Apache Proxy und Rewrite
So funktioniert Verbindungsaufbau und Nutzung einwandfrei. Keine schöne Lösung – ich würde das nur für WebDynpro’s nutzen.








Du muss angemeldet sein, um einen Kommentar zu veröffentlichen.