SFTP (Secure File Transfer Protocol) ist ein Netzwerkprotokoll, das es ermöglicht, Dateien sicher zu übertragen. Es ist eine erweiterte Version von FTP (File Transfer Protocol), die zusätzlich die Verschlüsselung von Daten und die Authentifizierung von Benutzern unterstützt. In diesem Artikel zeigen wir Ihnen, wie Sie mit Ansible einen SFTP-Server erstellen und konfigurieren können.
Ansible ist ein Open-Source-Automatisierungswerkzeug, das es ermöglicht, Aufgaben auf Remote-Hosts auszuführen. Es kann verwendet werden, um Server, Netzwerkgeräte und andere IT-Infrastruktur zu verwalten und zu konfigurieren. Einer der Vorteile von Ansible ist, dass es in der Lage ist, Aufgaben auf mehreren Hosts gleichzeitig auszuführen, was die Verwaltung von großen IT-Umgebungen vereinfacht.
Um einen SFTP-Server mit Ansible zu erstellen, benötigen Sie zunächst eine Maschine, auf der Ansible installiert ist. Dies kann entweder ein lokaler Rechner oder ein Remote-Host sein. Sobald Ansible installiert ist, müssen Sie ein Playbook erstellen, das die notwendigen Schritte zur Erstellung und Konfiguration des SFTP-Servers enthält. Ein Playbook ist eine Sammlung von Anweisungen in YAML-Format, die von Ansible ausgeführt werden.
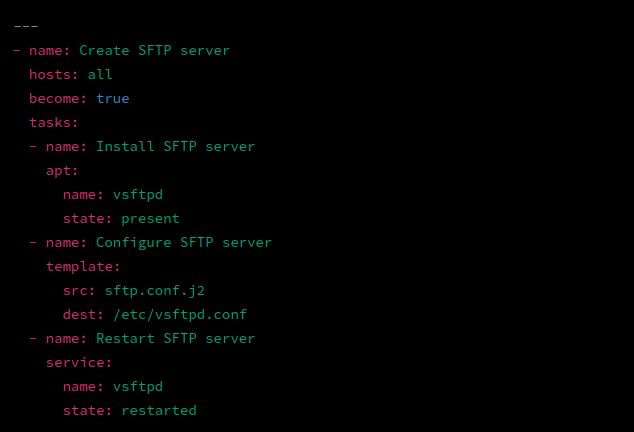
Ein Beispiel für ein Playbook zur Erstellung eines SFTP-Servers mit Ansible sieht wie folgt aus:
---
- name: Create SFTP server
hosts: all
become: true
tasks:
- name: Install SFTP server
apt:
name: vsftpd
state: present
- name: Configure SFTP server
template:
src: sftp.conf.j2
dest: /etc/vsftpd.conf
- name: Restart SFTP server
service:
name: vsftpd
state: restarted
Dieses Playbook führt folgende Schritte aus:
- Installation des SFTP-Servers vsftpd auf allen Hosts.
- Konfiguration des SFTP-Servers mithilfe einer Vorlage (sftp.conf.j2).
- Neustart des SFTP-Servers.
Die Vorlage sftp.conf.j2 enthält die Konfigurationsoptionen für
den SFTP-Server. Diese Optionen können je nach Anforderungen angepasst werden. Einige Beispiele für Optionen, die in der Vorlage enthalten sein können, sind:
anonymous_enable: Ermöglicht oder verhindert den Zugriff auf den SFTP-Server durch anonyme Benutzer.local_enable: Ermöglicht oder verhindert den Zugriff auf den SFTP-Server durch lokale Benutzer.write_enable: Ermöglicht oder verhindert das Schreiben auf den SFTP-Server.chroot_local_user: Einschränkung des Zugriffs von Benutzern auf ihr Home-Verzeichnis.
Sobald das Playbook erstellt wurde, kann es mit dem Befehl ansible-playbook ausgeführt werden. Nach Abschluss der Ausführung sollte der SFTP-Server erfolgreich erstellt und konfiguriert sein.
In diesem Artikel haben wir gezeigt, wie Sie mit Ansible einen SFTP-Server erstellen und konfigurieren können. Ansible bietet viele weitere Möglichkeiten, um IT-Infrastrukturen zu verwalten und zu automatisieren. Wenn Sie mehr über Ansible und seine Funktionen erfahren möchten, empfehlen wir Ihnen, die Dokumentation und Tutorials von Ansible zu lesen.
Im nächsten CCGL Workshop beschäftigen wir uns mit:
- Benutzerkonten und Berechtigungen: Um Benutzer auf dem SFTP-Server anlegen und verwalten zu können, können Sie Ansible-Module wie
user und group verwenden. Auch das Zuweisen von Berechtigungen an Benutzer oder Verzeichnisse kann mithilfe von Ansible-Modulen wie file oder acl erfolgen.
- Sicherheit: Um den SFTP-Server sicher zu machen, empfiehlt es sich, starke Passwörter für Benutzerkonten zu verwenden und Zugriff von unsicheren Netzwerken oder IP-Adressen zu beschränken. Auch das Aktivieren von SSL/TLS-Verschlüsselung kann die Sicherheit erhöhen.
- Monitoring: Um den Betrieb des SFTP-Servers zu überwachen, können Sie Ansible-Module wie
shell oder command verwenden, um regelmäßig Systeminformationen oder Protokolle auszulesen und zu analysieren. Auch das Einrichten von Benachrichtigungen bei Fehlern oder Ausfällen kann hilfreich sein.
- Skalierbarkeit: Wenn Sie vorhaben, den SFTP-Server für viele Benutzer oder große Dateien zu verwenden, empfiehlt es sich, die Leistung und Skalierbarkeit des Servers im Voraus zu planen. Dies kann beispielsweise durch das Hinzufügen von mehr Speicherplatz oder durch das Verteilen der Last auf mehrere Server erfolgen.
Ich hoffe, dass diese Tipps hilfreich sind und Ihnen bei der Erstellung von SFTP-Servern mit Ansible weiterhelfen! Wenn Sie weitere Fragen haben, zögern Sie nicht, mich zu kontaktieren.




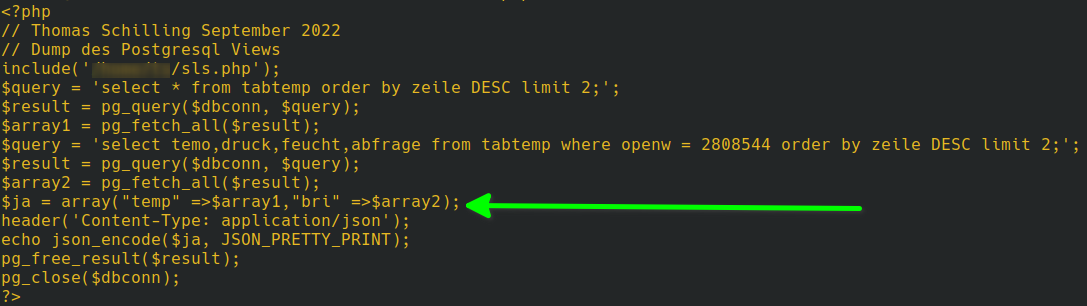

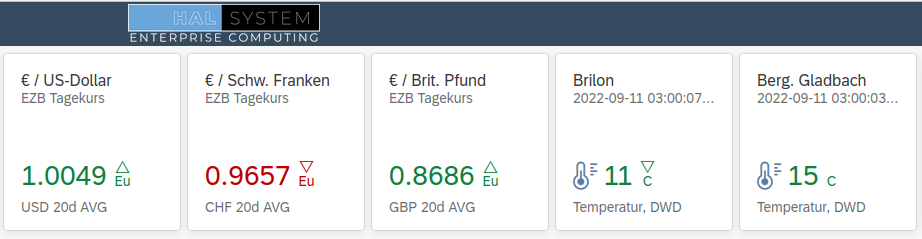
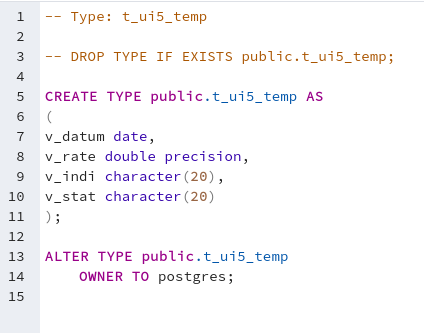
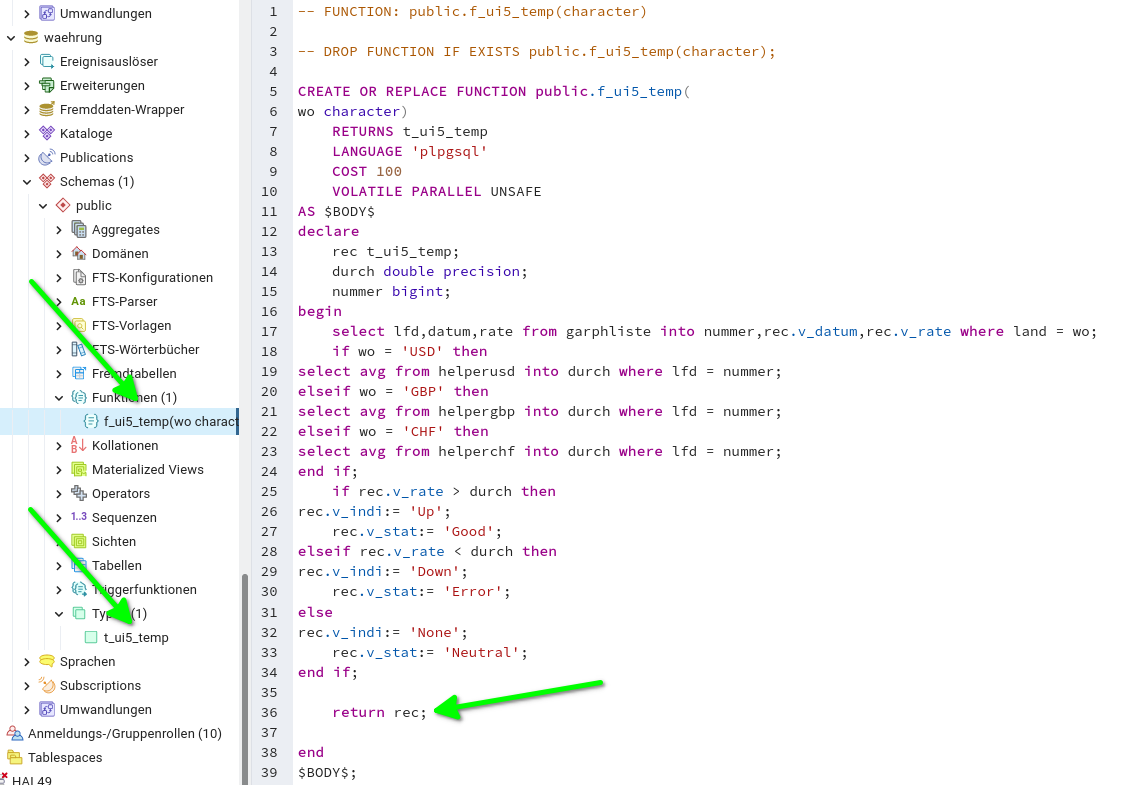





Du muss angemeldet sein, um einen Kommentar zu veröffentlichen.