Ich habe des Öfteren das Problem, das SSH Verbindungen über WLAN sporadisch abbrechen. Bei Backup’s ärgerlich – ich habe hier einen Tipp geschrieben – aber auch das verlieren von getunnelten RDP Verbindungen nervt. In Microsoft Windows Systemen nutze ich PuTTY für SSH Tunnel – mit Hilfe eines kleinen Batchfiles und dem Programm Plink aus dem PuTTY-Paket lässt sich das Problem elegant beheben.
Die Verbindungsparameter vereinbaren wir bequem im UI des Programms PuTTY und merken uns den Namen des gespeicherten Profils. Jetzt erzeugen wir ein Batchfile (Dateiendung .bat)
@echo off
:while
date /T
time /T
C:\Users\irgendwo\plink.exe -batch -N -load profil
if %errorlevel% neq 0 ( goto :while )
Die Argumente für Plink sind analog zu PuTTY. Wenn im Profil Username, Zertifikat, Tunnel hinterlegt ist, kann man mit -batch -N die Shell und jede Nachfrage unterdrücken. Das Batchfile zeigt lediglich Datum und Zeit des Connects sowie Reconnect an.
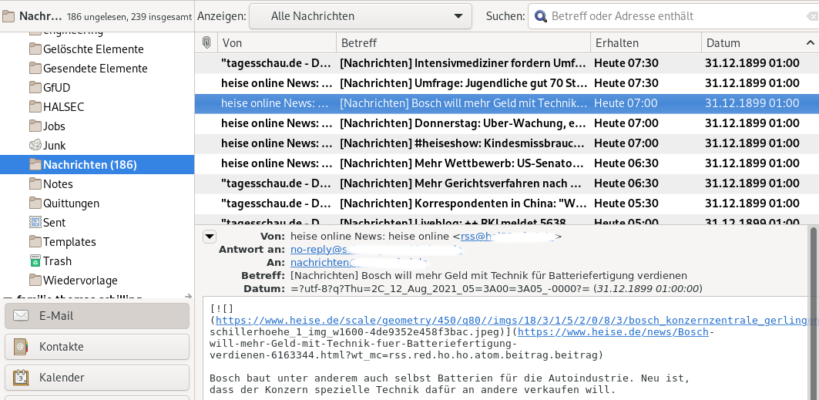
Nicht nur praktisch um allgemein auf dem Laufenden zu bleiben, es kann auch als Firmen internes Mitteilungsorgan genutzt werden. Eine Nachricht an die konfigurierte Mail Adresse wird sicher verteilt und archiviert.
auto. Ordner Nachrichten auf PC, Laptop oder Smartphone
Mailman Archiv
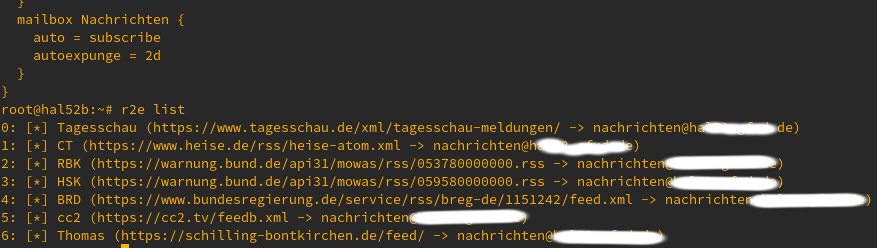
Konfiguration IMAP Ordner 48h Zeit der Vorhaltung. Liste der Feeds.
r2e holt also den RSS Feed ab und sendet ihn als gewöhnliche EMail. Im IMAP Server (hier Dovecot) ist die Lebenszeit der Nachrichten auf 48h konfiguriert. Wichtig, damit die Übersicht erhalten bleibt und der Nutzer nicht selbst löschen muss. Das EMail Postfach gehört Mailman und verteilt die Nachrichten in die Postfächer der entsprechenden Abbonenten und hält ein Archiv vor.
Das nur als Alternative zum ECM System. Welche Lösungen habt Ihr im Betrieb?
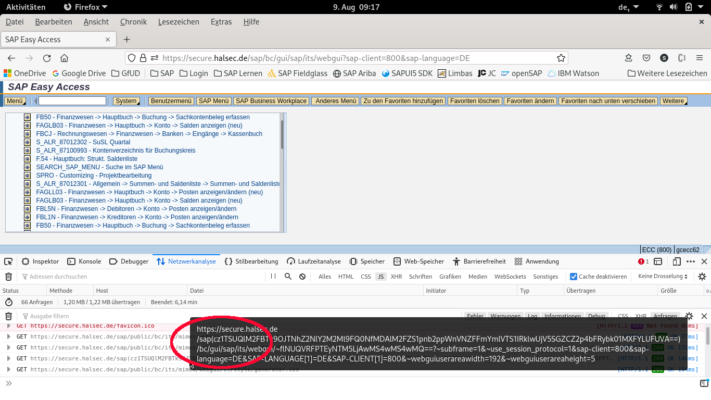
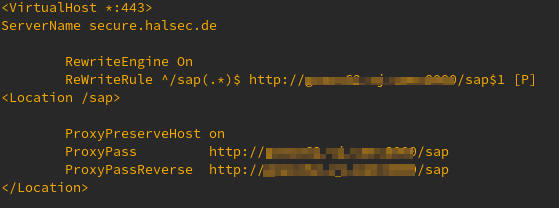
Das Apache2 Modul mod_proxy zur Anbindung des SAP ITS an die Aussenwelt funktioniert recht problemlos wenn es um WebDynpro’s geht.
Will man darüber hinaus auch die WebGUI Online nutzen, gibt es einen Stolperstein. Im Verbindungsaufbau zum WebGUI wird die Session ID (SSO) als POST in der URL ausgetauscht. Das sprengt die Direktive im Filter „/sap“ des Apache welcher dann das „/sap(“ nicht erkennt. Der Prozess bleibt für den User scheinbar stehen.
URL Rewrite im Anmeldeprozess
Apache Proxy und Rewrite
So funktioniert Verbindungsaufbau und Nutzung einwandfrei. Keine schöne Lösung – ich würde das nur für WebDynpro’s nutzen.
Das generieren von Zufallszahlen kann schwierig sein, wenn der Zyklus der Generierung mehrmals in einer Sekunde aufgerufen wird. Die Zufallszahl wird innerhalb der Sekunde gleich sein, benutzt man als rnd seed die Unixzeit.
Die Unixzeit ist eine 32Bit Zahl mit Vorzeichen und repräsentiert die Anzahl Sekunden seit 1.1.1970 00:00:00 Uhr. Im Klartext: 32Bit -1 Bit Vorzeichen = 31Bit. 2**31 = 2147483648 -1 (wir rechnen von 0 an) = 2147483647 als maximale Integer Zahl. Die Standardfunktionen srand und rand sind ebenfalls Funktionen welche eine 32Bit Zahl zurück geben. 32Bit Integer als rnd-seed ist die Unixtime, welche erst mit der Sekunde wechselt, weshalb die Vorgehensweise in dem Fall nicht empfehlenswert ist.
In der C Library stdlib.h existieren u.a. die Funktionen srand48 und lrand48. Für die Programmierung macht das keinen Unterschied: Das Seed bleibt 32Bit, genau so der Rückgabewert der Funktionen. Innerhalb der Funktion wird dem 32Bit Wert, 16Bit hinzu gefügt. Das Seed entspricht dann intern einem 13 stelligem Integer (mit Vorzeichen) – die drei zusätzlichen Stellen entsprechen den Millisekunden zur Unixzeit. Funktionsbeispiel:
#include
#include
#include
#include
int zufall(void)
{
char zu;
srand48((long int)time(NULL));
zu = (lrand48()/rand()) %3 + 1;
return zu;
}
So erhalte ich sehr schnell eine einstellige Zufallszahl zwischen 1 und 3.
Unser Nextcloud Dienst wird produktiv genutzt und Gruppen tauschen sich über Gruppenchats in Talk aus. Über die API von Nextcloud läßt sich sehr einfach maschinell und automatisiert Nachrichten versenden. Servernachrichten, neue Tickets vom Kunden oder das Papier im Drucker muss nachgefüllt werden – alles ist denkbar.
Es empfiehlt sich einen eigenen Bot User einzurichten. In den Gruppen, in die Nachrichten gesendet werden sollen, muss dieser User hinzu gefügt werden. Hier ein Beispiel in Python:
import os
# Minimal lt Nextcloud API Beschreibung
server = "https://deinServer.de/nextcloud/"
username = "bot"
password = "meinPW"
def NextcloudTalkSendMessage(channelId, message):
data = {
"token": channelId,
"message": message,
"actorDisplayName": "Nachricht",
"actorType": "",
"actorId": "",
"timestamp": 0,
"messageParameters": []
}
url = "{}/ocs/v2.php/apps/spreed/api/v1/chat/{}".format(server, channelId)
payload = json.dumps(data);
headers = {'content-type': 'application/json', 'OCS-APIRequest': 'true'}
resp = requests.post(url, data=payload, headers=headers, auth=(username, password))
print(resp)
# Die Gruppe bekommt Test Meldung
output = 'Test'
NextcloudTalkSendMessage('ien9wbax', output)
# Diese Gruppe sieht die Uptime der Maschine
output = os.popen("uptime").read()
NextcloudTalkSendMessage('ien9wbrk', output)
Auf die Reaktion der Anwender bin ich gespannt, wie nützlich das ist. Welche Erfahrung habt ihr?
Die Standardbibliotheken in Python machen es schon sehr bequem, trotz häufigem Typecasting, zum Beispiel JSON Datenquellen zu lesen, zu manipulieren und in diverse Datenbanken abzulegen.
In Zeile 14 laden wir uns einen JSON Datensatz der in Zeile 15 direkt in ein Daten Array dekodiert wird. In dem mehrdimensionalen Array können wir die Daten direkt mit dem korrektem Datentyp – spricht Integer, Float oder Date – bearbeiten. Probleme tauchen erst in den Zeilen 26,27,28 auf. Nämlich dann, wenn Stringmanipulationen (hier Concatenate) durchgeführt werden. Theoretisch geht’s; Praktisch kommt es häufiger zu Fehlern in der Formatierung weshalb ich hier konsequent Integer, Float und Date in String umwandel. Zeile 16 und 24 zeigt: Es wird erst mit Integer und Float gerechnet, das Ergebnis als String in Variabeln geschrieben. Zeile 29 ist nicht zu vergessen. Postgresql bekommt gerne ein Commit.
Nur für mich, habe ich mir mal eine kurze Übersicht der Corona Infektionszahlen programmiert. Nicht zuletzt um meiner IBM Cloud DB2 Datenbank eine Aufgabe zu geben. Sehr simpel:
import datetime
from tabulate import tabulate
import json
import urllib.request
from ibm import *
jsonurlD = urllib.request.urlopen('https://api.corona-zahlen.org/germany')
jsonurlRBK = urllib.request.urlopen('https://api.corona-zahlen.org/districts/05378')
dataD = json.loads(jsonurlD.read().decode())
dataRBK = json.loads(jsonurlRBK.read().decode())
datum = dataD['meta']['lastUpdate'][0:10]
sql = "select datum from corona order by datum desc limit 1"
stmt = ibm_db.exec_immediate(conn, sql)
letzte = ""
while ibm_db.fetch_row(stmt) != False:
letzte = str(ibm_db.result(stmt, 0))
if letzte != datum:
sdinz = str(round(dataD['weekIncidence'],1))
srinz = str(round(dataRBK['data']['05378']['weekIncidence'],1))
sdcase = str(dataD['cases'])
srcase = str(dataRBK['data']['05378']['cases'])
sddeath = str(dataD['deaths'])
srdeath = str(dataRBK['data']['05378']['deaths'])
sddcase = str(dataD['delta']['cases'])
srdcase = str(dataRBK['data']['05378']['delta']['cases'])
sdddeath = str(dataD['delta']['deaths'])
srddeath = str(dataRBK['data']['05378']['delta']['deaths'])
sql = """insert into corona(datum,dinz,rinz,dcase,rcase,ddeath,rdeath,ddcase,rdcase,dddeath,rddeath)
values('""" + datum + """',""" + sdinz + """,""" + srinz + """,""" + sdcase + """,""" + srcase + """,""" + sddeath \
+ """,""" + srdeath + """,""" + sddcase + """,""" + srdcase + """,""" + sdddeath + """,""" + srddeath + """)"""
ibm_db.exec_immediate(conn, sql)
ibm_db.free_result(stmt)
sql = "select datum,dinz,rinz,dcase,rcase,ddeath,rdeath,ddcase,rdcase,dddeath,rddeath from corona order by datum desc limit 20"
# 0 1 2 3 4 5 6 7 8 9 10
stmt = ibm_db.exec_immediate(conn, sql)
array1 = []
while ibm_db.fetch_row(stmt) != False:
array1.append([str(ibm_db.result(stmt, 0).strftime('%d.%m.%y')),str(ibm_db.result(stmt, 3)), \
str(round(ibm_db.result(stmt, 1),1)),str(ibm_db.result(stmt, 5)), \
str(ibm_db.result(stmt, 7)),str(ibm_db.result(stmt, 9)),str(ibm_db.result(stmt, 4)),str(round(ibm_db.result(stmt, 2),1)), \
str(ibm_db.result(stmt, 6)),str(ibm_db.result(stmt, 8)),str(ibm_db.result(stmt, 10))])
print('\n\n')
print(tabulate(array1,headers=['Datum','BRD-C', 'BRD-Inz','BRD-D', 'BRD-Delta', 'BRD-D-D','RBK-C', 'RBK-Inz','RBK-D', 'RBK-Delta', 'RBK-D-D'],tablefmt='pretty'))
print('\n\n')
ibm_db.close(conn)
Im direktem Vergleich zu Python mit Postgresql, ist die IBM_DB Python Bibliothek lobend zu erwähnen. In Zeile 32 ist ein Commit im Befehl ibm_db.exec_immediate implizit. Zeile 11 ist eigentlich „Ferkelei“. Ich schneide aus einem Timestamp die ersten 10 Stellen heraus um das Datum zu erhalten. Macht man nicht, aber ich muss auch hier ohnehin ein Cast zum String (für Zeile 29) durchführen. Datentyp in der Tabelle ist Date – es wird also beim lesen des Datensatzes (Zeile 36) wieder Typ Date gelesen und in Zeile 43 wieder konvertiert damit es für die Ausgabe in Zeile 49 korrekt darstellbar ist.
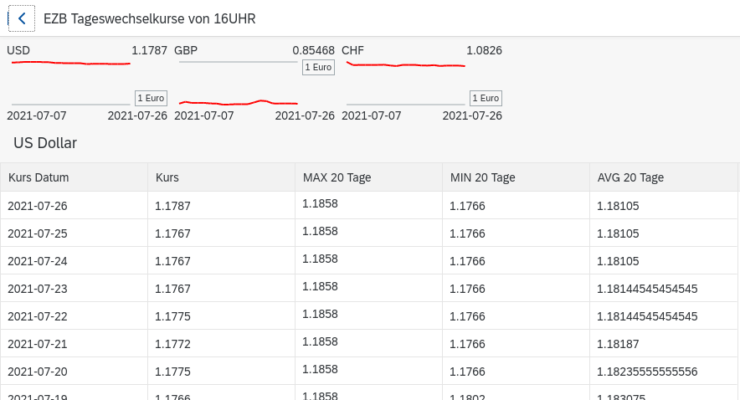
Zur Verarbeitung der Tageswechselkurse. Benutze ich für Tagesabschlüsse von Kassensystemen in Vorbereitung auf die Abschaffung des Euro Bargeldes. Es wird damit gerechnet, das auf andere Währungen zurück gegriffen wird und hier dient der EZB Tageskurs zur korrekten Wertstellung.
Im Vorfeld besorge ich die Daten die im XML Format angeboten werden. Sicher, XML kann auch verarbeitet werden. Für mich ist es schlicht eine Textdatei aus der ich mir die benötigten Daten heraus schneide. Aus dem XML benötige ich lediglich „RUB 87.1713“ zur weiteren Verarbeitung.
Produktiv programmiere ich häufig in COBOL und so ist das Beispiel „EZB Tageswechselkurs“ auch entstanden. Hier ist das Typecasting einmal anders herum: In Zeile 19 wird die Datensatz aufnehmende Variable für den Kurs mit dem Typ Alphanumerisch vereinbart. Mit der Zeile 22 wird eine weitere Variable mit dem Typ Numerisch, mit 5 vor- und 4 nach Kommastellen gesetzt. Das Typecasting findet in Zeile 37 statt. Ich nutze die numerische Variable hier aber nicht – in anderen Programmen verwende ich die Variable für Berechnungen. Im Beispiel nimmt die Datenbank den Typ Character an.
IDENTIFICATION DIVISION.
PROGRAM-ID. RATES.
AUTHOR. THOMAS SCHILLING.
DATE-WRITTEN. 11 JUNI 2021.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
SOURCE-COMPUTER. HAL52.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT RATES-FILE ASSIGN TO 'rates.txt'
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD RATES-FILE
DATA RECORD IS RATES-RECORD.
01 RATES-RECORD.
05 land PIC X(3).
05 FILLER PIC X(1).
05 rate PIC X(16).
01 EOF PIC A(1).
WORKING-STORAGE SECTION.
01 rateN PIC 9(5)V9(4).
01 pgconn USAGE POINTER.
01 pgres USAGE POINTER.
01 resptr USAGE POINTER.
01 resstr PICTURE x(80) based.
01 sqlstr PIC x(150).
77 dbcon PIC x(40).
77 neuezeile PIC X(1) VALUE x'00'.
PROCEDURE DIVISION.
PERFORM START-DB THRU START-DB-EXIT
OPEN INPUT RATES-FILE
PERFORM UNTIL EOF='Y'
READ RATES-FILE
AT END MOVE 'Y' TO EOF
NOT AT END
COMPUTE rateN = FUNCTION NUMVAL(rate)
PERFORM START-PUT THRU START-PUT-EXIT
END-READ
END-PERFORM.
PERFORM STOP-DB THRU STOP-DB-EXIT.
CLOSE RATES-FILE.
STOP RUN.
START-DB.
STRING
"user=meinUser " DELIMITED BY SIZE
"password=meinPW " DELIMITED BY SIZE
"dbname=meineDB" DELIMITED BY SIZE
neuezeile
INTO dbcon
END-STRING.
CALL "PQconnectdb" USING
BY REFERENCE dbcon
RETURNING pgconn
END-CALL.
START-DB-EXIT.
START-PUT.
STRING
"INSERT INTO eubank(" DELIMITED BY SIZE
"land,rate)" DELIMITED BY SIZE
" VALUES ('" DELIMITED BY SIZE
land
"', " DELIMITED BY SIZE
rate
" );" DELIMITED BY SIZE
x"00"
into SQLSTR
END-STRING
call "PQexec" using
by value pgconn
by reference SQLSTR
returning pgres
end-call
CALL "PQclear" USING BY VALUE pgres END-CALL.
START-PUT-EXIT.
STOP-DB.
CALL "PQfinish" using by value pgconn end-call
set pgconn to NULL.
STOP-DB-EXIT.
Ein Commit ist auch hier in der C-Library PQexec implizit.
Die IBM Cloud DB2 hat mich begeistert. Wenn ich noch einmal einen Workshop veranstalten sollte, ist das eine praktische und sauber programmierte Lösung.
Nachdem ich mir die wesentlichen Cloud Anbieter wie Mircosoft Azure, Amazon AWS und IBM Cloud intensiv angesehen habe, war die Entscheidung nicht schwer. IBM war und ist die Nummer 1. Wert etwas tiefer zu gehen






Du muss angemeldet sein, um einen Kommentar zu veröffentlichen.