Belege scannen und archivieren ist Dauerthema in der Systementwicklung. In den Workshops taucht schon einmal die Frage nach den Diensten für automatisierte Belegverarbeitung auf. Also: Belege scannen, verbuchen und archivieren. Natürlich habe ich mich damit vor längerem beschäftigt – nehmen wir das als neuen Workshop im CCGL auf.
Ich persönlich halte nicht viel davon, da es doch sehr fehleranfällig ist. Die Systeme müssen ständig trainiert und kontrolliert werden. Auch in Top-Systemen beschäftigt sich der Buchhalter mit Korrekturbuchungen wenn die Belege tatsächlich als Papier mit der Snail-Mail im Unternehmen ankommen. Ich zeige auch warum; meine Gedanken möchten Initalfunke für den Workshop sein. In der Realität arbeiten wir immer öfter mit der eRechnung.
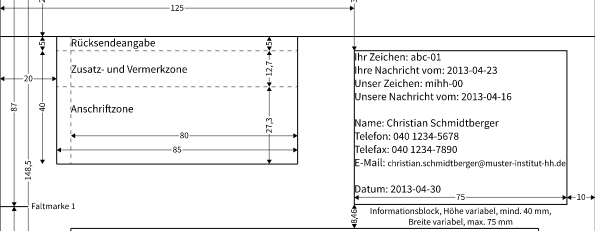
Zwei Wege zur automatischen Verarbeitung sehe ich. Die bekannten Dienste lesen Kreditor, Belegnummer, Belegdatum und Summe aus dem Beleg. Wie findet man die Angaben?
Die einfach Art lehnt sich an eine schon früher besprochene Vorgehensweise an (Link). Der Scan liegt da als Fließtext vor. Mit entsprechenden awk und perl Scripten können Schlüßelwörter gefiltert werden.
Die anspruchsvollere Lösung habe ich vor 15 Jahren programmiert und wurde produktiv genutzt. Es basiert auf der Vermutung, das die wesentlichen Angaben einer Rechnung oft an der selben Stelle zu finden sind. Es existiert eine Norm (Link).
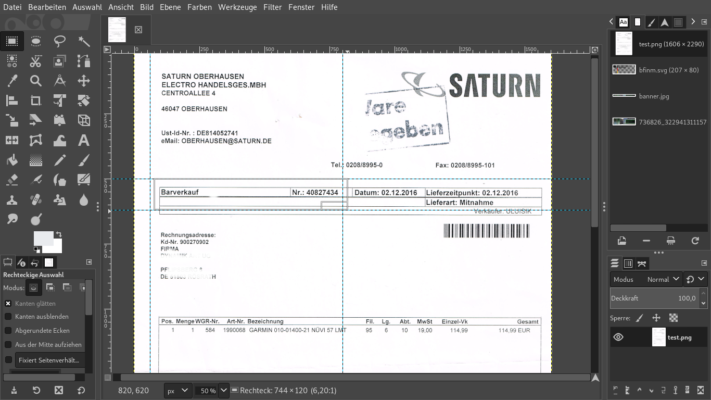
Schauen wir uns den Beispielbeleg an. Der Beleg hat eine Breite und eine Länge in Pixeln. Anstatt den gesamten Text zu durchsuchen, kann ich auch nur einen definierten Ausschnitt betrachten. Wird nur der Ausschnitt gelesen, haben wir Belegart und Belegnummer. Hier verwende ich Python – sehr flexibel und eigentlich selbsterklärend:
from pdf2image import convert_from_path
image = convert_from_path("test.pdf")[0]
import pytesseract
import re
snummer = re.compile("[^0-9]")
sbart = re.compile("[^a-zA-Z]")
beleg = image.crop((52,500,800,600))
text = pytesseract.image_to_string(beleg)
def sauberenummer(text):
text = re.sub(snummer,"",text)
return text
def sauberebeleg(text):
text = re.sub(sbart,"",text)
return text
print(sauberebeleg(text))
print(sauberenummer(text))
Schauen wir in Zeile 10: direkte Position des Ausschnitts in Pixel! Also Beginn x,y und Ende x,y in absoluten Pixeln. Zum Beispiel GIMP zeigt die Cursorposition in der Statusleiste in Pixeln an. Produktiv würde ich mit dem Verhältnis zur Gesamtgröße arbeiten. pytesseract ist nicht so flexibel wie das Paket tesseract selbst, dennoch sehr schnell und sicher.
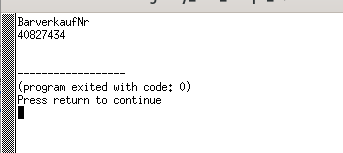
Ich wende hier zum lesen zwei verschiedene Filter an. Zeile 7 definiert einen Filter der nur Zahlen zwischen 0 und 9 zurück gibt – Zeile 8 nur Buchstaben ohne Umlaute. Die Funktionen in den Zeilen 14 und 18 wenden den Filter an und ersetzen jedes andere Zeichen durch „“ (Nichts).
Hier sehen wir die Problematik. „BarverkaufNr“ ist keine Belegart. Es müssen einige Routinen geschrieben werden um hier eine Rechnung verarbeiten zu können. Die Belegnummer kann so weiter verarbeitet werden.
Ich bin sehr gespannt auf Eure Vorschläge!
Du muss angemeldet sein, um einen Kommentar zu veröffentlichen.